Splitting comma-separated values in MySQL
- Blog
- Analytics Platform as a Service (AnPaaS)
- Data democratization
- Developer experience (DevX)
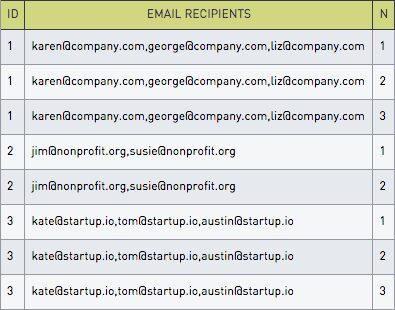
Every once in a while, a quick decision is made to store data in a comma-separated fashion, and the SQL analyst is left to pick up the pieces during analysis. Let’s take an example from Sisense’s own schema: Each Sisense for Cloud Data Teams dashboard has a comma-separated list of users who receive that dashboard by email every day. Here’s what it looks like:

Let’s say we want to do a simple analysis: Which users receive the most dashboards by email? If we’re using Postgres, regexp_split_to_table comes to the rescue.
MySQL users, however, are in the dark. In this post, we’ll show how to split our comma-separated string into a table of values for easier analysis in MySQL.
Making a table of numbers
To get started, we’ll need a table that contains numbers at least as big as the length of our longest comma-separated list. We like Sisense’s Views feature for this, but in a pinch, a temporary table also works:
create temporary table numbers as (
select 1 as n
union select 2 as n
union select 3 as n
...
)
Joining our table to numbers
The next thing we’ll want to do is create the structure of our resulting table. We need a row for each email address in each list.
To do that, let’s join the numbers table to our original dashboards table. We’ll use the numbers to restrict the number of rows to the length of each list:
select *
from dashboards
join numbers
on char_length(email_recipients)
- char_length(replace(email_recipients, ',', ''))
>= n - 1Let’s take this in pieces. First is char_length, which returns the number of characters in a string. replace(email_recipients, ‘,’, ”) removes commas from email_recipients. So char_length(email_recipients) – char_length(replace(email_recipients, ‘,’, ”)) counts the commas in email_recipients.
By joining on the number of commas >= n – 1, we get exactly the number of rows as there are email_recipients!
Here are the results:
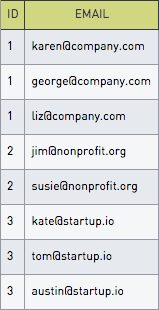
Selecting each item in the list
We now have the list duplicated exactly the right number of times, and as a bonus, we have a column of numbers that we can use as an array index!
We just need to select the item in the list that corresponds to n. For this, we’ll turn to MySQL’s handy substring_index function. Here’s the SQL:
select
id,
substring_index(
substring_index(email_recipients, ',', n),
',',
-1
) as email
from dashboards
join numbers
on char_length(email_recipients)
- char_length(replace(email_recipients, ',', ''))
>= n - 1substring_index returns the substring starting or ending at the i’th occurrence of the specified delimiter, where i is the third argument. We use it once with n to find the nth comma and select the entire list after that comma.
Then we call it again with -1 to find the first remaining comma, and select everything to the left of that. With this combination, we find the whole string between the nth and (n+1)th comma. That’ll be the nth email recipient!
Here’s the resulting table:
Putting it all together
Now that we have our data schematized, a simple group-and-count can tell us who the top users of the email feature are!
select email, count(1) from (
select
id,
substring_index(
substring_index(email_recipients, ',', n),
',',
-1
) as email
from dashboards
join numbers
on char_length(email_recipients)
- char_length(replace(email_recipients, ',', ''))
>= n - 1
) email_recipients_by_dashboard
group by 1This gives us our results:

As we can see, Joel is leading the pack!
Get a feel for frictionless analytics, 7 days, hands-on.
Free trial




Subscribe to the Sisense newsletter
Get monthly insights on building smarter products with AI-powered analytics, from industry trends to real Sisense use cases.