SQL GROUP BY — Everything you need to know
- Blog
- Developer experience (DevX)
A brief tutorial
Group by is one of the most frequently used SQL clauses. It allows you to collapse a field into its distinct values. This clause is most often used with aggregations to show one value per grouped field or combination of fields.
Consider the following table:
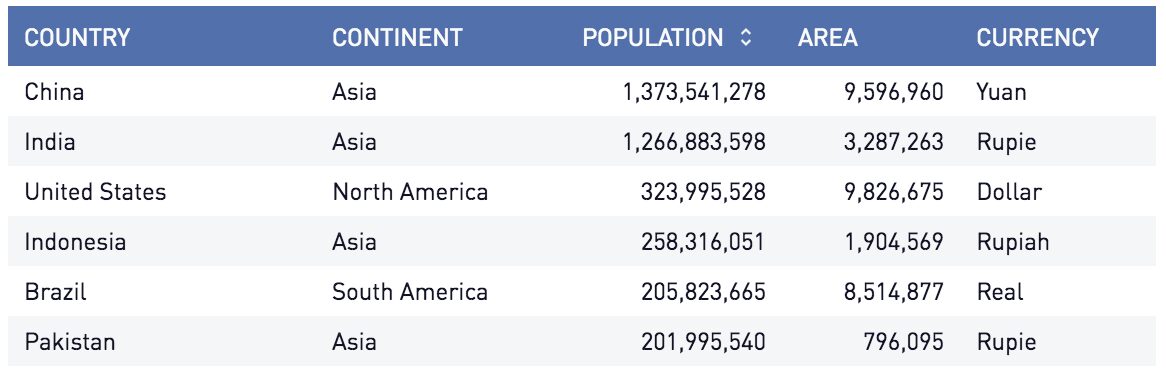
We can use an SQL group by and aggregates to collect multiple types of information. For example, an SQL group by can quickly tell us the number of countries on each continent.
-- How many countries are in each continent?
select
continent
, count(*)
from
countries
group by
continent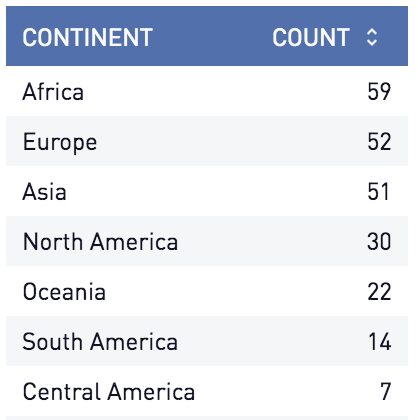
Keep in mind when using SQL GROUP BY:
- Group by X means put all those with the same value for X in the same row.
- Group by X, Y put all those with the same values for both X and Y in the same row.
More interesting things about SQL GROUP BY
1. Aggregations can be filtered using the HAVING clause
You will quickly discover that the where clause cannot be used on an aggregation. For instance:
select
continent
, max(area)
from
countries
where
max(area) >= 1e7
group by
1will not work, and will throw an error. This is because the where statement is evaluated before any aggregations take place. The alternate having is placed after the group by and allows you to filter the returned data by an aggregated column.
Using having, you can return the aggregate filtered results!
2. You can often GROUP BY column number
In many databases, you can group by column number as well as column name. Our first query could have been written:
select
continent
, count(*)
from
base
group by
1and returned the same results. This is called ordinal notation and its use is debated. It predates column based notation and was SQL standard until the 1980s.
- It is less explicit, which can reduce legibility for some users.
- It can be more brittle. A query select statement can have a column name changed and continue to run, producing an unexpected result.
On the other hand, it has a few benefits.
- SQL coders tend toward a consistent pattern of selecting dimensions first and aggregates second. This makes reading SQL more predictable.
- It is easier to maintain on large queries. When writing long ETL statements, I have had group by statements that were many, many lines long. I found this difficult to maintain.
- Some databases allow using an aliased column in the group by. This allows a long case statement to be grouped without repeating the full statement in the group by clause. Using ordinal positions can be cleaner and prevent you from unintentionally grouping by an alias that matches a column name in the underlying data. For example, the following query will return the correct values:
-- How many countries use a currency called the dollar?
select
case when currency = 'Dollar' then currency
else 'Other'
end as currency --bad alias
, count(*)
from
countries
group by
1
But this will not, and will segment by the base table’s currency field while accepting the new alias column labels:
select
case when currency = 'Dollar' then currency
else 'Other'
end as currency --bad alias
, count(*)
from
countries
group by
currency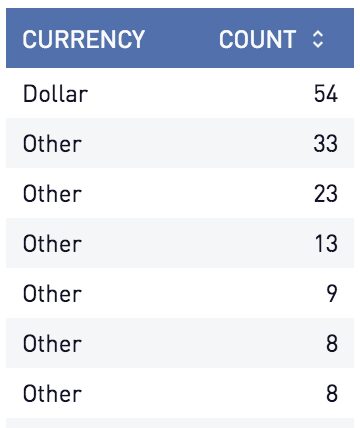
This is ‘expected’ behavior, but remain vigilant.
A common practice is to use ordinal positions for ad hoc work and column names for production code. This will ensure you are being completely explicit for future users who need to change your code.
3. The implicit GROUP BY
There is one case where you can take an aggregation without using a group by. When you are aggregating the full table there is an implied SQL group by. This is known as the in SQL standards documentation.
-- What is the largest and average country size in Europe?
select
max(area) as largest_country
, avg(area) as avg_country_area
from
countries
where
continent = 'Europe'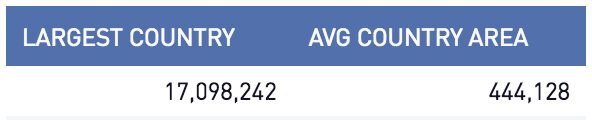
4. GROUP BY treats Null as groupable value, and that is strange.
When your data set contains multiple null values, group by will treat them as a single value and aggregate for the set.
This does not conform to the standard use of null, which is never equal to anything including itself.
select null = null
-- returns null, not TrueFrom the SQL standards guidelines in SQL:2008
“Although the null value is neither equal to any other value nor not equal to any other value — it is unknown whether or not it is equal to any given value — in some contexts, multiple null values are treated together; for example, the treats all null values together.”
5. MySQL allows you to GROUP BY without specifying all your non-aggregate columns
In MySQL, unless you change some database settings, you can run queries like only a subset of the select dimensions grouped, and still get results. As an example, in MySQL this will return an answer, populating the state column with a randomly chosen value from those available.
select
country
, state
, count(*)
from
countries
group by
countryThat’s all for today! Group by is a commonly used keyword, but hopefully you now have a clearer understanding of some of its more nuanced uses.
Keep exploring




Subscribe to the Sisense newsletter
Get monthly insights on building smarter products with AI-powered analytics, from industry trends to real Sisense use cases.