A primary key is a unique identifier given to a record in our database, which we can use when querying the database or in order to join multiple sources. This article will discuss the concept of surrogate keys and show some examples of when and how to apply them using simple SQL.
General guidelines for selecting primary keys
Before we dive into natural vs. surrogate keys, let’s recall four important rules to follow when selecting a primary key for your data model:
The primary key must be unique for each record. A primary key with duplicates will lead to inaccurate queries with duplicated counts and totals. If two customers are assigned the same primary key, their sales activity will be unintentionally blended together. If the customer is accidentally duplicated, their sales activity will also be duplicated. Database architects refer to this as a loss of referential integrity.
The primary key must apply uniform rules for all records. Whether your key is strictly numeric, alphanumeric, or a random system-generated value, each record must be programmed in a consistent format. This format must exist despite whatever complexities there are in the business requirements. An inconsistent format can lead to difficult data analysis, especially in parent/child data relationships.
The primary key must stand the test of time. A key based off of contextual data at the present time, may not have the same contextual meaning later. For example, if a customer ID key is based on customer name, what happens when a customer is acquired or reorganized? Changing key formats should be avoided at all costs. Changing keys will require changing all stored procedures referencing the new key in any JOINs or WHERE clauses, as well as UPDATEs to all existing references to the old key in all of your database tables.
The primary key must be read-only. In order to stand the test of time, primary keys should never be edited. Edited primary keys can have typos (123123 vs 132123), varying formats based on the user’s preference (1 vs 000001), and allow for overwriting a previously deleted record. Never allow anyone to edit the value of primary keys.
Selecting a Primary key: Surrogate vs. Natural keys
First, let’s go over the difference between these two forms of primary keys:
A natural key is a key that has contextual or business meaning (for example, in a table containing STORE, SALES, and DATE, we might use the DATE field as a natural key when joining with another table detailing inventory).
A natural key can be system-generated, but natural keys are at least partially determined by a manual process. Some natural keys are totally manually generated. One of the most widely recognized uses of a natural key is a stock ticker symbol – i.e. MSFT, APPL, and GOOGL. Natural keys serve as a great primary key when contextual meaning is important.
A surrogate key is a key which does not have any contextual or business meaning. It is manufactured “artificially” and only for the purposes of data analysis. The most frequently used version of a surrogate key is an increasing sequential integer or “counter” value (i.e. 1, 2, 3). Surrogate keys can also include the current system date/time stamp, or a random alphanumeric string.
See Sisense in action: [sisense-dashboard-example name=”ec-control-room”]
When should you stick to natural keys in your data model?
The main advantage of natural keys is in their simplicity and in the fact that the data maintains its original context. They will often be (relatively) easy to recognize to people viewing the data, and relying on natural keys reduces the need to enrich the data using custom SQL. Additionally:
Natural keys are great for multiple data types in the database. Natural keys allow the user to easily identify the data type from the key, even when multiple data types use similar key formats. Financial databases frequently format their keys using a natural and sequential key together.
Expense Report: ER-123
Timesheets: TS-123
AR Invoices: INV-123
Even though all three records contain a sequential ID of 123, the natural key prefix allows the user to immediately identify different data types.
Natural keys work well when connecting two systems with two different primary key formats. Thus for example, we can use
Natural keys make for a more easy-to-understand GUI. A customer ID such as GOOGL is easy for a user to recognize (for instance, you likely knew this stock ticker symbol is for Google). Easier recognition also allows for easier search.
Drawbacks of using natural keys
While it might be tempting and initially easier to rely on existing natural keys, this could prove problematic when scaling the data model, or in a more complex environment, which we will demonstrate using an example of stock tickers:
Natural keys do not apply uniform rules for each record. Designators or variables in the natural key make the key difficult to query and understand after the fact. For example, stock ticker symbols of preferred shares have a multitude of designators, including P, PR, and /PR. Trying to query for the designator P (SELECT * FROM stock_quotes WHERE stock_ticker_symbol like %P) would return all results where the stock ticker symbol ends in P, regardless if the symbol is actually preferred stock or not.
Natural keys do not stand the test of time. Symbols which might have been business meaning could become meaningless, or bear a different meaning in the future. Thus, for example, the symbols GOOG and GOOGL do not accurately represent the reorganization of the company from Google to Alphabet.
Natural keys can be easily confused with each other. Sticking with the previous example – when Twitter was ready to launch their IPO under the ticker TWTR, many investors bought from a defunct electronics company named Tweeter, trading under the ticker TWTRQ. Because TWTR and TWTRQ contain the same first four letters, many investors unintentionally invested in the wrong stock. Tweeter later changed their ticker symbol to THEGQ, which could also be misconstrued with GQ Magazine (a privately held company under Conde Nast).
Advantages of using surrogate keys
As mentioned, a surrogate key sacrifices some of the original context of the data. However, it can be extremely useful for analytical purposes for the following reasons:
Surrogate keys are unique. Because surrogate keys are system-generated, it is impossible for the system to create and store a duplicate value.
Surrogate keys apply uniform rules to all records. The surrogate key value is the result of a program, which creates the system-generated value. Any key created as a result of a program will apply uniform rules for each record.
Surrogate keys stand the test of time. Because surrogate keys lack any context or business meaning, there will be no need to change the key in the future.
Surrogate keys allow for unlimited values. Sequential, timestamp, and random keys have no practical limits to unique combinations.
Combining Natural and Surrogate Keys
Certain business scenarios might require keeping the natural key intact as a means for users to interact with the database. In these cases …
If a natural key is recommended, use a surrogate key field as the primary key, and a natural key as a foreign key. While users may interact with the natural key, the database can still have surrogate keys outside of the users’ view, with no interruption to user experience.
If a natural key must be used without an additional surrogate key, be sure to combine it with a surrogate key element. In our financial database example, Expense Reports (ER-123) have a natural key is used in conjunction with a surrogate sequential key. This format prevents many of the natural key side effects listed above.
An example of adding a surrogate key using Custom SQL
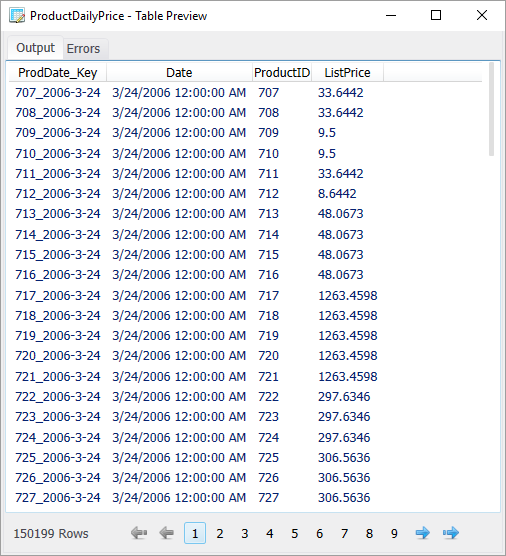
In the following example, we will look at a table containing historical data about product prices. By using a custom SQL expression in the Sisense ElastiCube Manager, we create the surrogate key ProdDate_Key, which in this case is created by combining the other fields into a single, unique identifier that can easily be queried later.
Original:
SQL used to add surrogate key:
SSELECT DISTINCT
tostring(ProductID)+'_'+tostring(getyear(Date))+'-'+tostring(getmonth(Date))+'-'+tostring(Getday(Date)) AS Prod_Date_Key,
Date,
PH.ProductID,
PH.ListPrice
FROM [ProductListPriceHistory] PH JOIN [AllDates] ON Date between PH.StartDate AND PH.EndDate